今天学习了判断字符串匹配操作中的kmp算法,现对此进行一个简单的梳理和归纳,思路主要来源于知乎上对kmp算法的几篇详细分析文章:https://www.zhihu.com/question/21923021 另外B站上也有kmp算法的视频演示教学: https://www.bilibili.com/video/BV1jb411V78H?from=search&seid=13467499309274367749&spm_id_from=333.337.0.0
字符串的匹配问题
字符串的匹配是对字符串的常见操作,具体来说就是:给定字符串A和B,让我们来判断B是否为A的字串,如果是,B出现在A串的什么位置?其中,A称作主串,B称作模式串。
c++

BF算法(Brute-Force)
在谈及Kmp算法之前,我们需要先了解一下BF算法,这样才能让KMP的算法优势更为明显。Brute—Force,顾名思义,这是一种暴力的解法。其思路也很简单:给定主串A和模式串B,将A和B的每个字符逐个比较,如果一致则继续比较下一个字符,当匹配到不一致时就将模式串后移一位,然后重新从模式串的首位开始对比,重复先前步骤。


例子
例子:给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。
代码实现
class Solution {
public int strStr(String haystack, String needle) {
int haylen = haystack.length();
int needlen = needle.length();
//特殊情况
if (haylen < needlen) {
return -1;
}
if (needlen == 0) {
return 0;
}
//主串
for (int i = 0; i < haylen - needlen + 1; ++i) {
int j;
//模式串
for (j = 0; j < needlen; j++) {
//不符合的情况,直接跳出,主串指针后移一位
if (haystack.charAt(i+j) != needle.charAt(j)) {
break;
}
}
//匹配成功
if (j == needlen) {
return i;
}
}
return -1;
}
}BF算法时间复杂度讨论及改进思路
设主串长度为n,模式串长度为m,在BF算法中,完成一趟匹配至少要进行一次比较,最多要进行m次比较。BF算法最多进行n-m+1趟匹配,因此最坏情况下一共要进行m(n-m+1)次比较,考虑到主串的长度应远大于模式穿,所以时间复杂度为O(m*n)。最坏情况是每一趟匹配都在最后一个字符失配,如a=”cccccc”, b=”ccb”。
改进思路:BF算法的缺点很明显,那就是进行了太多没必要的比较。因此,我们考虑降低比较的趟数,有些趟字符串比较是有可能会成功的;有些则毫无可能。如果我们跳过那些绝不可能成功的字符串比较,就可以减少不必要的比较趟数来降低算法的复杂度。
KMP算法
前缀和后缀
在使用KMP算法之前,我们需要了解几个概念:前缀、后缀、相同前后缀的最大长。
abcdef的前缀:a、ab、abc、abcd、abcde(注意:abcdef不是前缀)
abcdef的后缀:f、ef、def、cdef、bcdef(注意:abcdef不是后缀)
abcdef的公共最大长:0(因为其前缀与后缀没有相同的)
ababa的前缀:a、ab、aba、abab
ababa的后缀:a、ba、aba、baba
ababa的相同前后缀的最大长:3(因为他们的公共前缀后缀中最长的为aba,长度3)
利用用相同前后缀的最大长度设计KMP算法
如下图所示,模式串在与主串配对中,当i指向a,j指向c时失配,那么主串和模式串的前6位是相同的。又因为模式串的前6位,它的它的前4位前缀和后4位后缀是相同的,因此主串i之前的4位和模式串的开头4位是相同的。因此我们只需要将j移动到最大相同前后缀中,前缀的末尾字符的后一位,再次和i指向的字符进行逐个比对即可。因此,问题转变成了如何来求解j指向字符之前的子串的最长公共前后缀的长度呢?因为有了这个长度,我们才能知道到底要移动多少位置。因此,我们就要去了解kmp算法的核心——next数组的求解。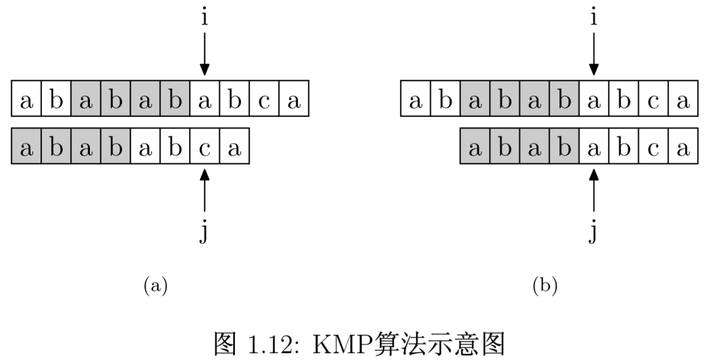
next数组
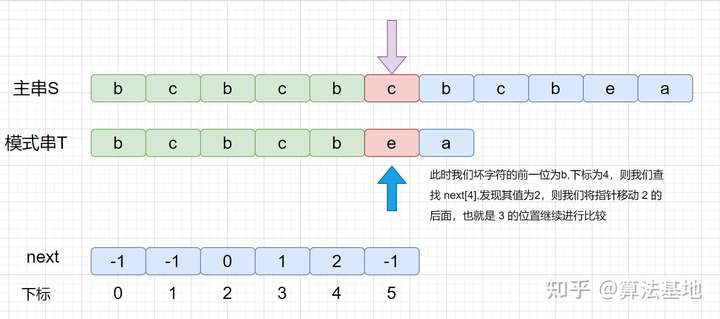
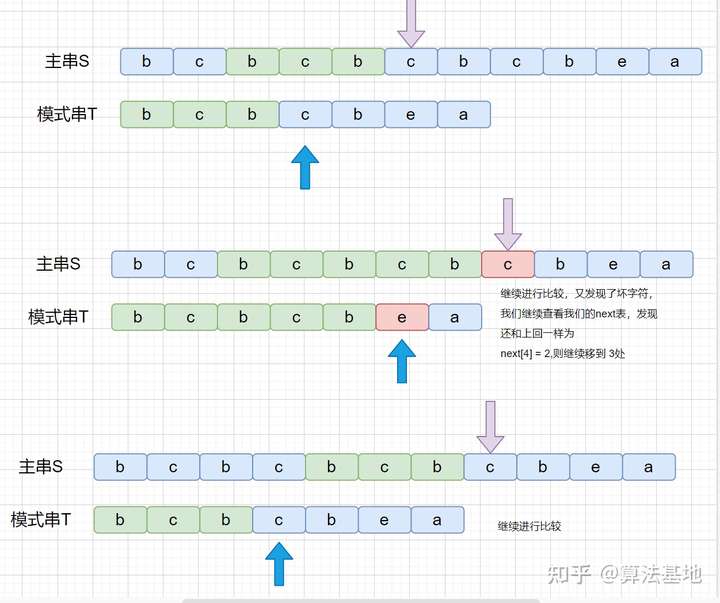
KMP中有一个数组,这个数组叫做next数组,它存放的是最长公共前后缀中,前缀的结尾字符下标。如下图示:

学会使用了next数组后,我们就可以利用它完成KMP算法。
代码实现
下面给出KMP算法的Java语言实现:
public class KmpTest {
public int strStr(String haystack, String needle) {
//haystack为主串 needle为模式串
//两种特殊情况
if (needle.length() == 0)
return 0;
if (haystack.length() == 0)
return -1;
// char 数组
char[] hasyarr = haystack.toCharArray();
char[] nearr = needle.toCharArray();
//长度
int halen = hasyarr.length;
int nelen = nearr.length;
//返回下标
return kmp(hasyarr, halen, nearr, nelen);
}
public int kmp(char[] hasyarr, int halen, char[] nearr, int nelen) {
//获取next数组
int[] next = next(nearr, nelen);
int j = 0;
for (int i = 0; i < halen; i++) {
/*发现不匹配的字符,然后根据next数组移动指针,移动到最大公共前后缀的
前缀的后一位*/
while (j > 0 && hasyarr[i] != nearr[j]) {
j = next[j - 1] + 1;
//如果已经超出长度,直接返回不存在
if (nelen - j + i > halen) {
return -1;
}
}
//如果相同就将指针同时向后移动,比较下个字符。
if (hasyarr[i] == nearr[j]) {
++j;
}
//遍历完整个模式串,返回模式串的起点下标
if (j == nelen)
return i - nelen + 1;
}
//若遍历完全部都没有匹配 那就从这里返回-1 匹配失败
return -1;
}
public int[] next(char[] needle, int len) {
//定义next数组
int[] next = new int[len];
//初始化
next[0] = -1;
int k = -1;/*初始化k+1为串首字符的下标,needle[i]始终为子串的串尾
下标。先通过k比较首字符,当首字符比较完毕后来判断剩余字符*/
for (int i = 1; i <len ; i++) {
while (k != -1 && needle[k + 1] != needle[i]) {
k = next[k];
}
if(needle[k+1]==needle[i])
k++;
next[i]=k;
}
return next;
}


